Inferoa: Inference-native Tokenmaxxing Agent Harness for Loop Engineering

Most agents call models as if inference were a black box.
The agent loop lives in one place, routing policy in another, serving behavior somewhere else, and context management becomes a last-minute fight with the window. That split is tolerable for one-turn chat. It breaks down when agents run for hours, recover from failures, compress context, warm prefix cache, route between model paths, and still need to prove the work at the end.
Prefix cache stability is ignored. Routing is bolted on later. Context is pasted until it fits. Users pay for that gap.
Inferoa = Infer(Inference-native)o(Tokenmaxxing Loop Engineering)a(Agent Harness).
Inferoa is an Inference-native Tokenmaxxing Agent Harness for Loop Engineering. It is built for recursive long-horizon goals: define the outcome once, then the agent loop keeps inspecting, changing, testing, reflecting, and continuing until the work is proven.
That is what inference-native means here: Inferoa starts from the inference stack and co-designs loop engineering around tokenmaxxing: prefix-cache discipline, context optimization with RTK and CodeGraph, intelligent routing through vLLM Semantic Router, high-throughput vLLM serving with vLLM Engine, vLLM Omni multimodal capability, and native goal, plan, and autoresearch loops with tokenmaxxing observability.

What Breaks
Long-horizon agents are not one prompt. They are many turns of planning, repo inspection, shell commands, edits, retries, compaction, cache warmup, route selection, and verification. If the harness treats every turn as generic chat traffic, it throws away the optimization surface underneath it.
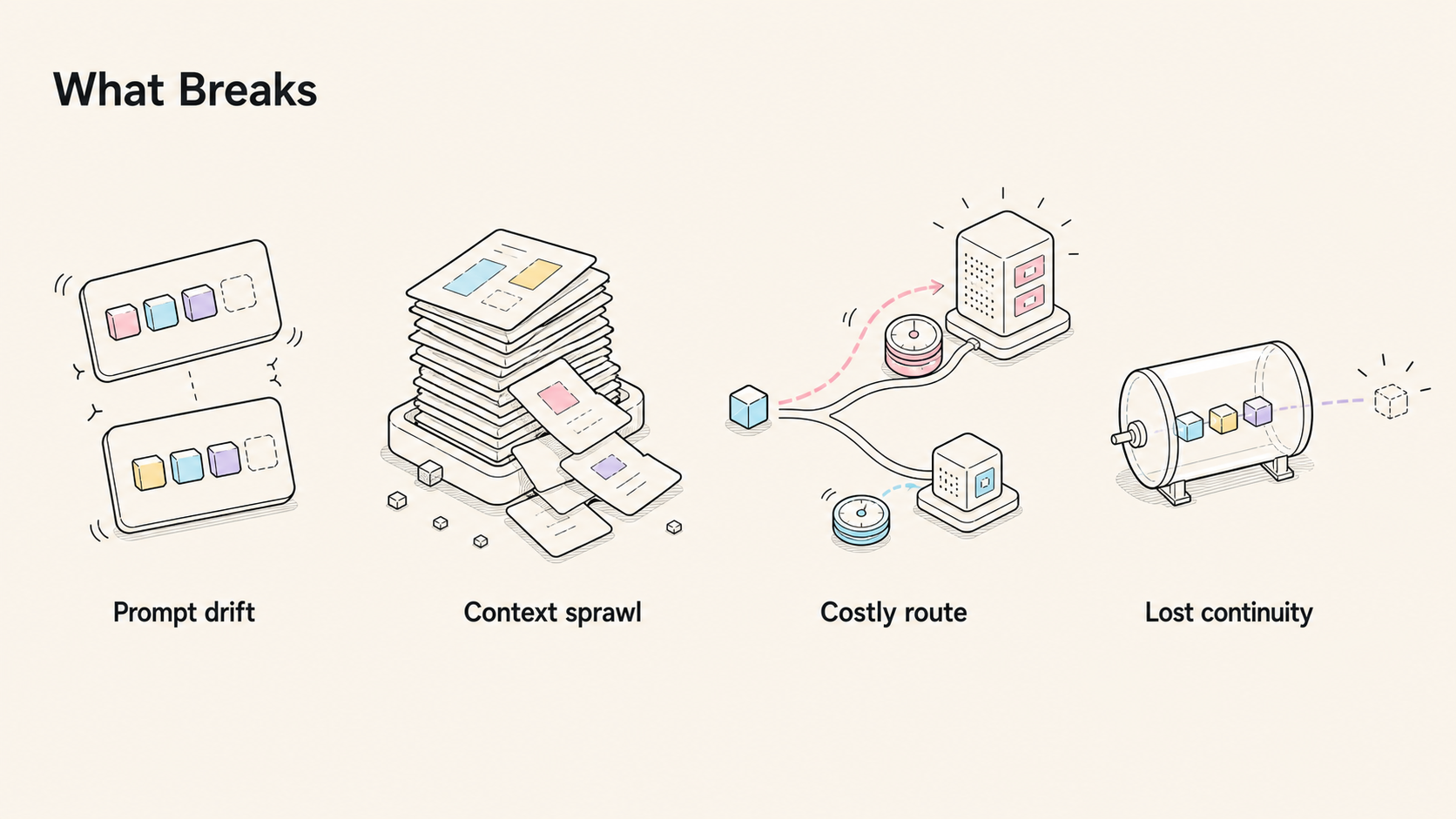
The failure modes are familiar:
- prompt shape drifts, so prefix cache cannot be reused reliably;
- context selection becomes "paste more" instead of "select better";
- cheap, private, or mechanical turns still take expensive model paths;
- compression preserves a summary but loses continuity;
- multimodal work becomes a disconnected side call;
- serving and cache signals arrive too late to shape the next action.
Inferoa treats those as harness design problems, not analytics problems.
What Changes
Inferoa makes inference behavior visible to the agent loop. The point is not to add another dashboard. The point is to let the runtime choose better prompts, better context, better routes, and better recovery behavior while the task is still running.
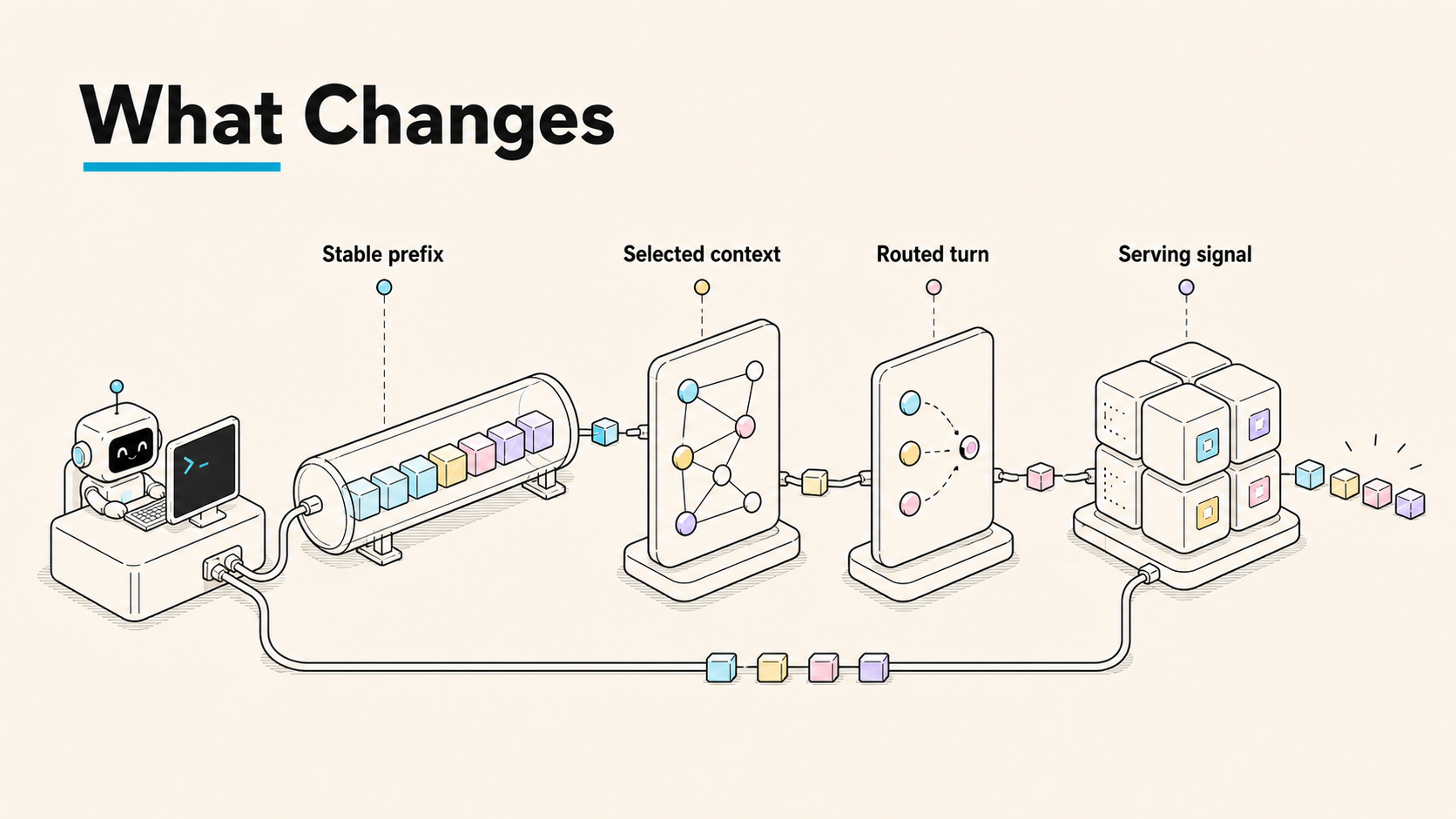
| Surface | Substrate | What Inferoa Makes Native | Why It Matters |
|---|---|---|---|
| Loop Engineering | Inferoa Goal Mode | Recursive long-horizon goals, horizons, candidate work, reflection, and completion evidence | The engineering loop keeps running until the work is proven |
| Agent Harness | Inferoa | Sessions, tools, plans, autoresearch, resources, recovery, and prefix-cache discipline | Long work gets a durable runtime while preserving reusable prompt prefixes |
| Context Optimization | CodeGraph, RTK | Compression, graph-shaped repo context, bounded tool output, and evidence selection | The model sees evidence, not raw sprawl |
| Intelligent Routing | vLLM Semantic Router | Model paths respond to cost, safety, privacy, capability, and session pressure | Turns can route between self-hosted vLLM models and external frontier models |
| Model Serving | vLLM Engine, vLLM Omni | High-throughput, memory-efficient serving and multimodal endpoints stay visible to the harness | Self-hosted paths make cost, safety, privacy, and data sovereignty controllable when an external frontier model is unnecessary |
This is the core design: the agent is not merely calling an inference system. It is shaped by it.
Goal Mode: Loop Engineering For Long-Horizon Work
Prompt engineering improves the next answer. Loop engineering designs the
system that keeps deciding what to do after that answer. In Inferoa, /goal is
the entry point: it starts a recursive long-horizon goal, expands work through
horizons, preserves evidence, and requires reflection before completion.
Goal Mode is deliberately not just a persistent note in the prompt. It gives the harness a durable outcome, a visible Horizon 0 orientation, a strategy, candidate work, step status, verification evidence, and a completion report. That is the difference between asking an agent for the next step and engineering the loop that keeps taking the next step.
Inferoa At A Glance
Inferoa is a terminal-first harness, but the product surface is not just a shell. It makes long-horizon state visible while the agent works.
Run /goal to start a long-horizon recursive goal. The agent can decompose
work, update steps, attach evidence, reflect between horizons, and avoid
mistaking an empty checklist for a finished goal.
Plan mode turns ambiguous scope into an inspectable decision. A plan can stay in drafting, move to approval, or become executable context without becoming a hard runtime failure.
Autoresearch mode makes the evaluation loop native: define the experiment, run the harness, record failures, patch the implementation, and keep the metric trail inside the same session.
Tokenmaxxing is the savings ledger for prefix-cache reuse, context optimization, RTK tool-output savings, recent turn usage, and model-selection pressure. This is the place to see whether the harness is actually tokenmaxxing the session, not just reporting token usage after the fact.
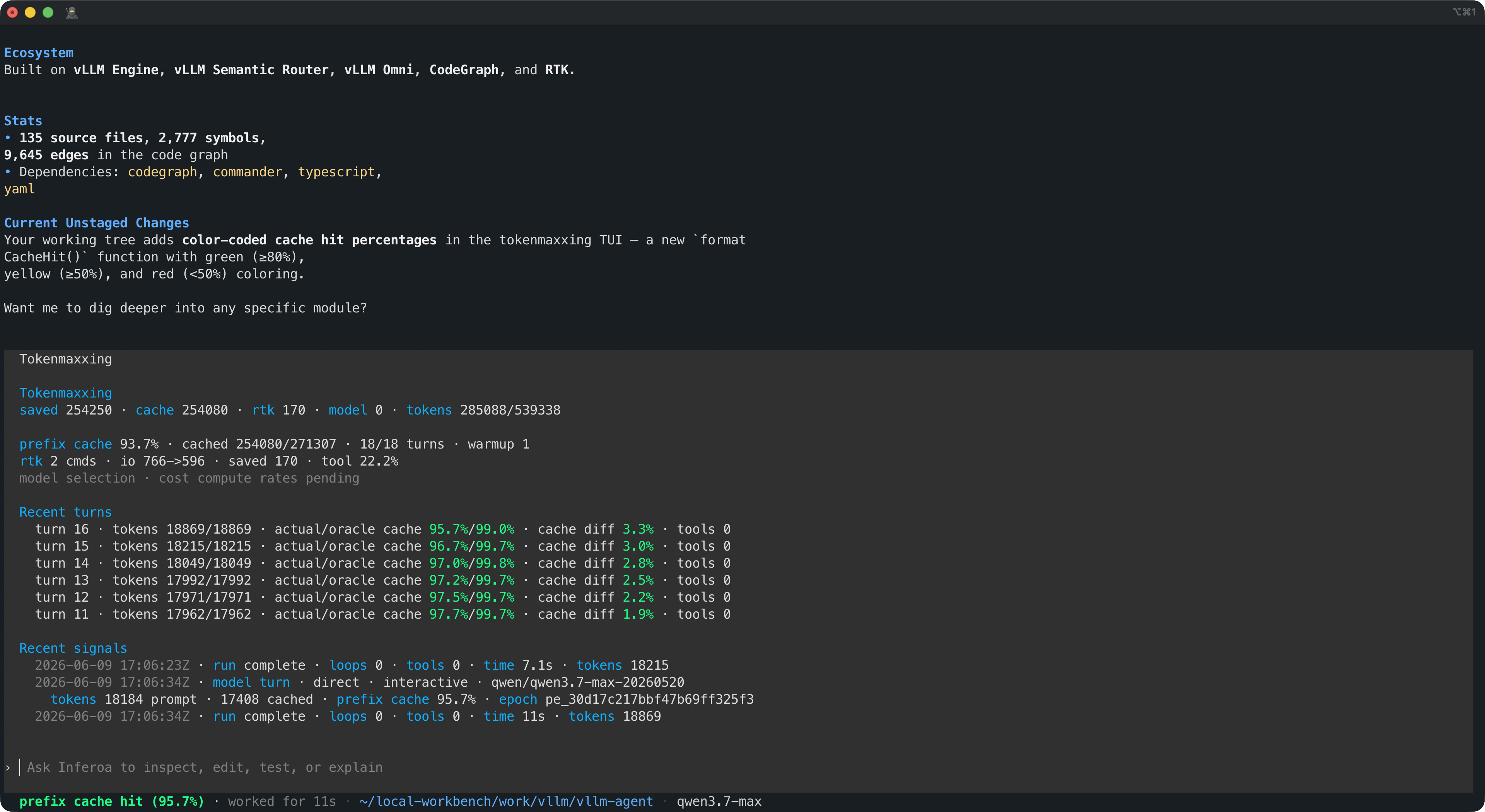
The core command surface stays small: /goal for durable objectives, /plan
for inspectable scope, /autoresearch for metric-driven iteration, and
/tokenmaxxing for the savings ledger across prefix cache,
CodeGraph and
RTK context savings, recent turn usage, and
model-selection cost pressure.
Proof Of Value
The value story is not one benchmark score. It is whether the tokenmaxxing path stays stable, measurable, and cheaper as the horizon grows. The public eval is deliberately split into measured stress runs and calibrated projections: measured runs check runtime invariants and continuity; projections ask what happens if the measured shape is carried to 1k-10k loops.
Key results:
- Prefix cache and continuity: measured profiles kept one prompt epoch, one tool schema hash, and one cache salt while cache reuse improved after warmup. A 256-turn compression regression preserved continuity markers and archive pointers, and 1k-10k projections were calibrated from measured tail slope instead of claimed as live 10k-request runs.
- CodeGraph context reduction: CodeGraph-style symbol/range selection saved 80.8% of inspected context.
- RTK tool-output reduction: RTK command records saved 61.4% of command-token footprint.

- Routing economics: the Routeworks leaderboard makes the inference-cost tradeoff visible on a log scale. At similar accuracy, routed paths can sit at 1/10 or even 1/100 of a frontier-heavy route's cost.
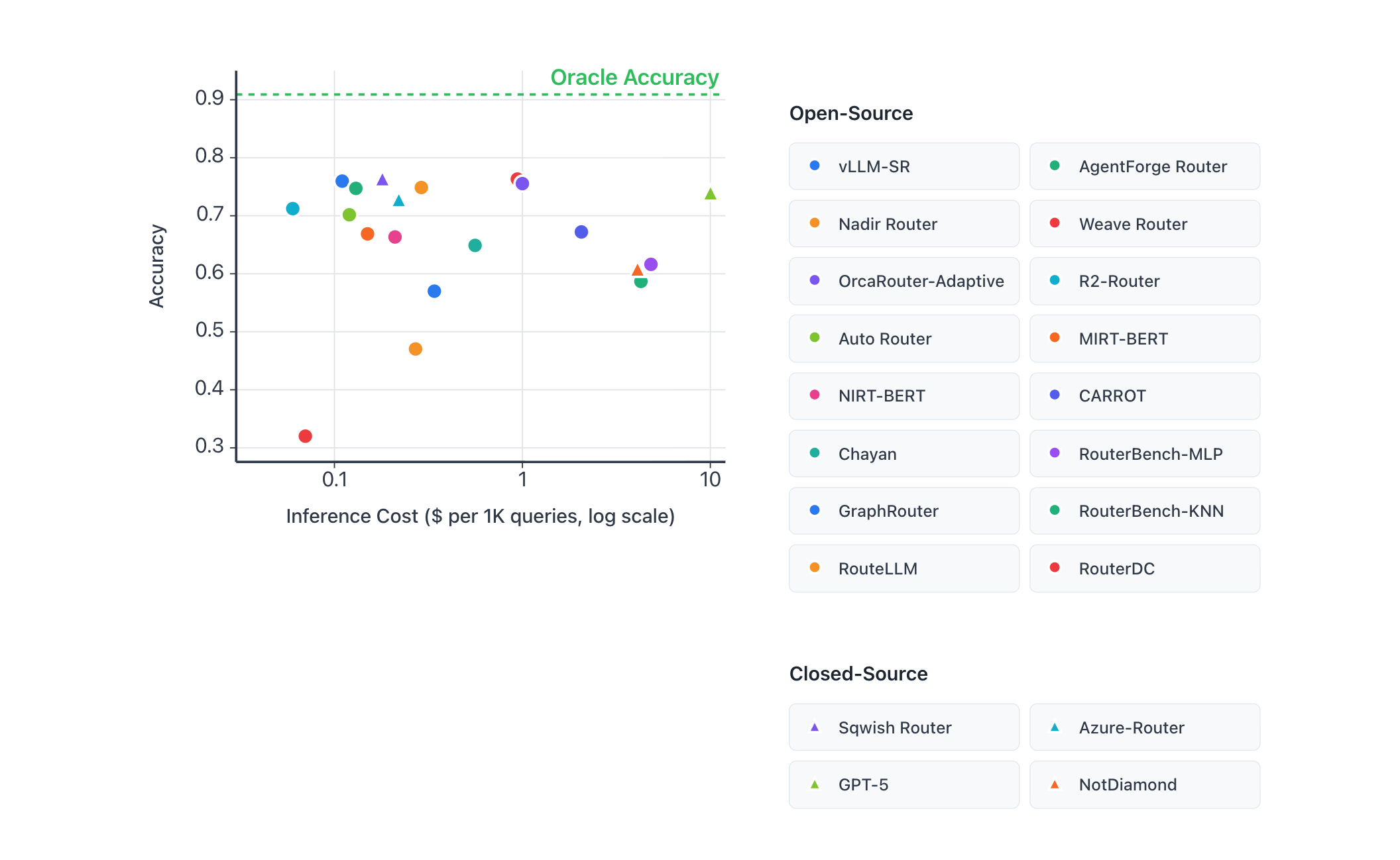
The exact numbers will move with workload, model pricing, and local RTK command corpus. The direction is the important part: long-horizon agents need a harness that protects stability, preserves continuity through compression, and uses every inference surface available.
Built With The Inference Stack
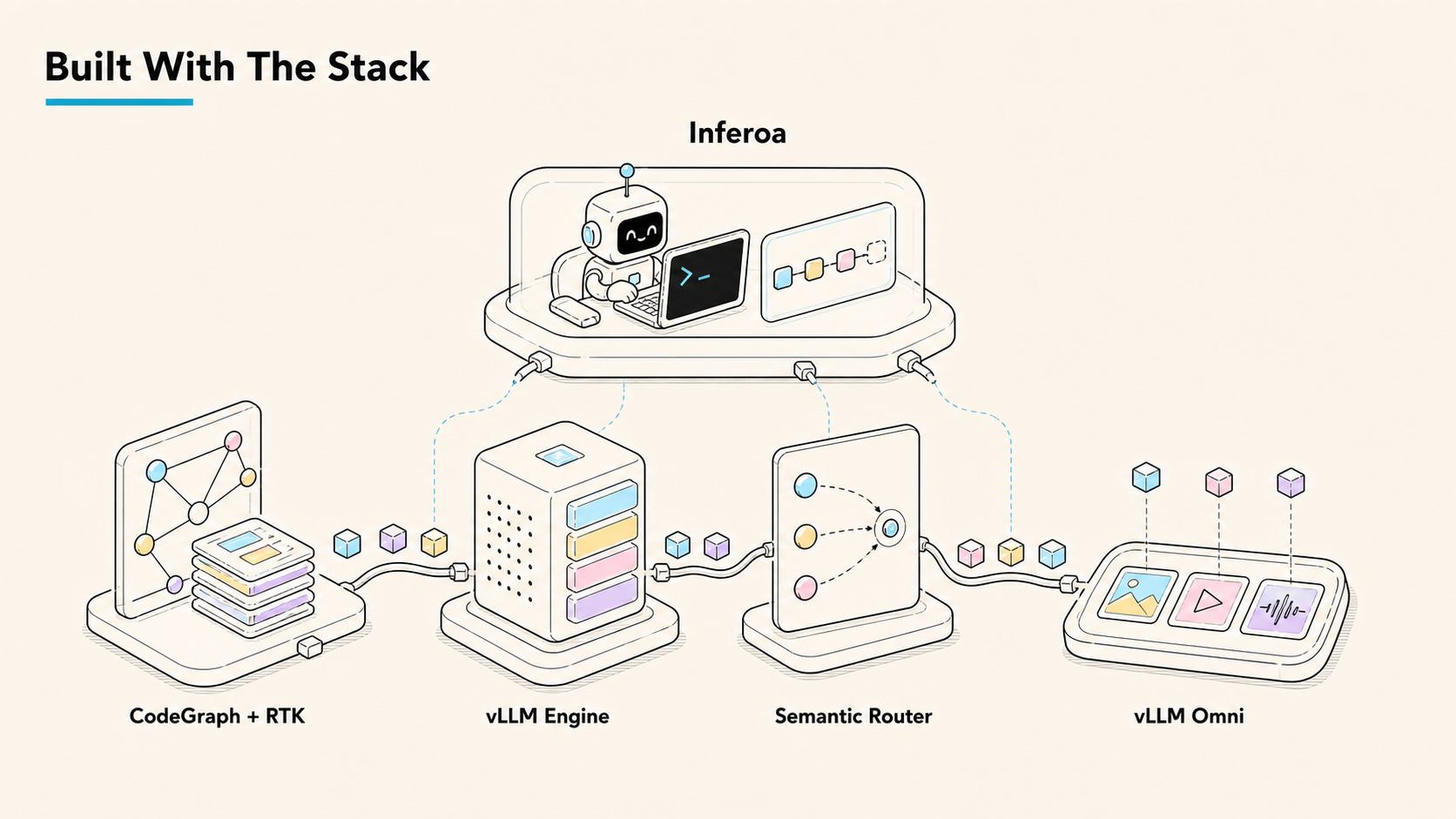
vLLM Ecosystem
Inferoa starts with the vLLM ecosystem because vLLM exposes the right surfaces: serving behavior, routing, multimodal paths, endpoint signals, and prefix-cache economics.
- vLLM Engine provides high-performance OpenAI-compatible inference and the prefix-cache behavior Inferoa protects across long sessions.
- vLLM Semantic Router brings model routing into the agent loop so routes can respond to cost, safety, privacy, capability, and session pressure.
- vLLM Omni brings image, video, and audio understanding or generation into the same durable agent contract.
Context Optimization
Inferoa also uses the context optimization projects that make long-horizon agent loops practical:
- CodeGraph turns repository context into graph-shaped symbol and range evidence.
- RTK rewrites command-heavy tool output into compact records that preserve evidence while reducing token pressure.
Inferoa is the harness layer above that stack: the place where long-horizon agent behavior and inference behavior meet.
Try It
npm install -g inferoa@dev
inferoa setup
inferoa
The larger goal is simple: agents should not waste the inference stack they are already paying for. Inferoa makes those signals native to the loop.