Inferoa: TokenMaxxing for Inference-Native Loop Engineering

The next step for coding agents is not a longer prompt. It is a better loop.
In a normal chat session, you are the loop. You remember the objective, decide the next step, inspect tool output, ask for another pass, and judge whether the result is good enough. That works for short tasks. It starts to break when the work spans many files, many tools, many attempts, or many hours.
Loop Engineering is the practice of designing that control loop instead of hand-steering every prompt. A loop needs an objective, memory, tools, feedback, verification, and a decision about what happens next.
Inferoa is built for that shift. It is an inference-native TokenMaxxing agent harness: a runtime that treats the loop as the unit of work, and treats every step inside that loop as an inference workload.
That second part matters. Long-running agents do not just need more autonomy. They need better inference behavior. As turns accumulate, prompt prefixes drift, cache reuse collapses, stale evidence fills context, model routing gets harder, and serving choices start to shape the cost and reliability of the work.
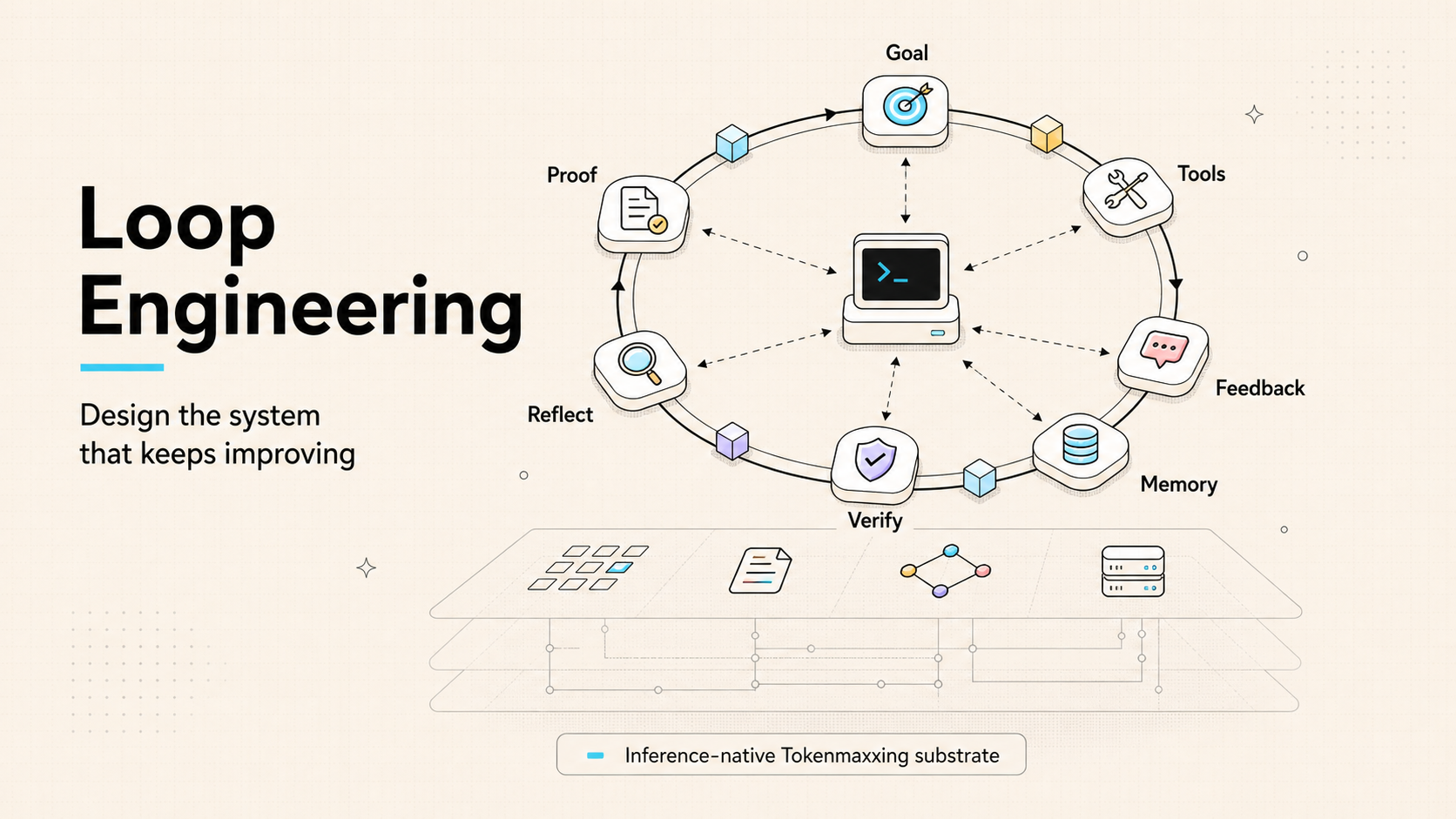
This is where Inference Native and TokenMaxxing become practical, not decorative. The loop has to see the substrate it is consuming: tokens, cache, context, routes, endpoints, and model capacity. TokenMaxxing is the discipline of spending tokens where they move the work forward, protecting reusable prefixes, compressing what no longer needs to be verbatim, and routing each step to the model path that fits the job.
Inferoa brings those pieces into one terminal-first harness: durable loops, verification evidence, memory and context control, prefix-cache discipline, intelligent routing through vLLM Semantic Router, high-throughput serving with vLLM Engine, vLLM Omni multimodal capability, and TokenMaxxing observability across the work.
